- English
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
What Is an NPU and How Does It Work in AI Devices?
Catalog

What Is an NPU?
A Neural Processing Unit (NPU) is a specialized processor designed to handle artificial intelligence tasks more efficiently than a general-purpose processor. Its main role is to accelerate neural network operations used in features such as image recognition, voice processing, object detection, and real-time AI inference. Unlike a CPU, which is built to manage many different computing tasks, an NPU is focused on AI-related calculations. It is optimized to process large amounts of data at the same time, making it suitable for workloads that require fast pattern recognition and decision-making. In modern devices, NPUs help AI features run directly on local hardware instead of depending fully on cloud servers. This allows smartphones, smart cameras, robots, vehicles, and edge devices to respond faster while using less power. Because of this, NPUs have become an important part of modern intelligent systems.
Core Architecture and Processing Modules of an NPU
An NPU is built from several specialized hardware modules that work together to process neural network workloads quickly and efficiently. Instead of sending every operation through one general-purpose processor, the workload is divided across dedicated hardware blocks that continuously process data in parallel. This structure improves AI inference speed, reduces unnecessary data movement, lowers power consumption, and helps maintain efficient memory usage.
During AI processing, data flows through multiple stages inside the processor. Input data first enters the computing pipeline, where large-scale mathematical operations are executed. Intermediate results then move through activation processing, tensor acceleration, image-related operations, and memory optimization hardware before the final output is produced. Because these modules operate together in a coordinated sequence, the NPU can maintain high throughput even when running large neural network models.
Core Computing and Activation Modules
The main computing engine inside an NPU is the Multiply-Accumulate (MAC) unit. Most neural network workloads repeatedly perform multiplication and addition across very large datasets, so this hardware handles the majority of AI computation during inference. When input data enters a neural network, values are multiplied by stored weight values and then added together to generate new outputs. This process repeats continuously across many neural network layers.
Modern NPUs often contain hundreds or thousands of MAC units operating simultaneously. Instead of calculating one operation at a time, the hardware distributes workloads across many parallel execution paths. Large batches of AI data move through the processor together, greatly improving inference speed while keeping latency low. In image recognition systems, for example, MAC units repeatedly scan groups of pixels and combine filter values to detect edges, textures, shapes, and patterns. In language models, the same hardware performs large-scale vector and matrix operations to process tokens and relationships between words.
After these mathematical calculations are completed, the results move into the Activation Function module. Neural networks depend on nonlinear activation functions to process complex relationships within data. Without activation processing, the network would only perform simple linear calculations and could not handle advanced AI tasks effectively.
This module executes functions such as ReLU, Sigmoid, and Tanh directly in hardware. Incoming values are quickly transformed according to the selected activation rule. ReLU, for example, removes negative values while preserving positive outputs, helping the network focus on stronger feature signals during inference. Since activation processing occurs repeatedly across every neural network layer, dedicated acceleration hardware helps reduce delays and prevents the main computing units from becoming overloaded.
Tensor and Spatial Data Processing Modules
NPUs also include specialized hardware for handling tensor operations and spatial data processing. Almost every modern AI model relies on tensors, which are multi-dimensional data structures used to organize information across dimensions such as width, height, channels, feature layers, and batches. Large amounts of tensor data continuously move between neural network layers during inference.
The Tensor Acceleration Unit processes these tensor structures directly in hardware. Operations such as tensor multiplication, reshaping, transformation, and accumulation execute much faster than on general-purpose processors. This dedicated acceleration becomes especially important in transformer architectures, computer vision systems, large language models, and real-time AI applications that require very high throughput.
Alongside tensor processing, NPUs also contain modules designed for 2D and spatial data operations commonly used in image and video workloads. Computer vision systems constantly resize, reorganize, filter, and move large amounts of pixel data before deeper AI analysis begins. Handling these tasks separately improves efficiency and reduces pressure on the main computing engine.
During image processing, the hardware manages operations such as downsampling, feature-map movement, image copying, resizing, cropping, and spatial data transfer. For example, high-resolution video captured by a camera may first be resized and reorganized before entering the neural network pipeline. This reduces computational load while preserving important visual information needed for object detection and scene analysis.
Memory Optimization and Data Compression Modules
Modern AI models require large amounts of memory to store neural network weights, tensors, and intermediate data. Constantly transferring this information between memory and computing hardware increases bandwidth usage, latency, and power consumption. To reduce this overhead, NPUs include dedicated Data Compression and Decompression modules.
Before data is stored in memory, repeated patterns and weight values are compressed into smaller formats. During execution, the compressed information is quickly restored and sent directly into the computing pipeline. This reduces memory traffic and allows more AI data to remain inside high-speed local memory closer to the processor.
Advanced compression methods can often reduce model size several times while maintaining nearly the same inference accuracy. This becomes especially important in smartphones, embedded systems, smart cameras, wearable electronics, and other edge AI devices where memory capacity and power efficiency are limited.
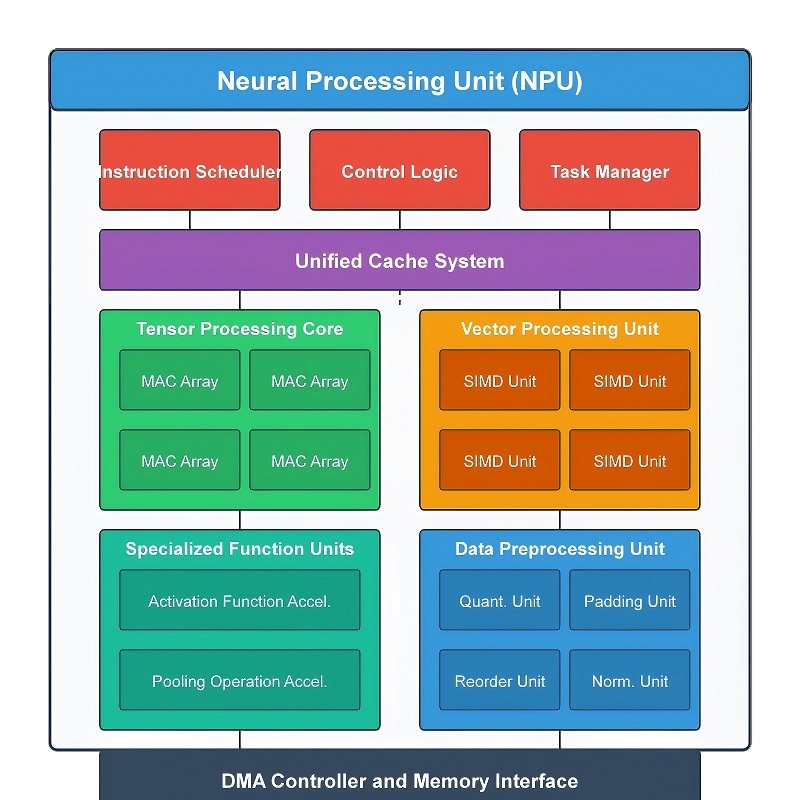
How These Modules Work Together
The performance of an NPU does not rely on a single hardware block. Its efficiency comes from how all processing modules operate together as a coordinated pipeline.
A typical AI workload begins with large-scale mathematical computation inside the MAC units. Intermediate results then pass through activation processing to introduce nonlinear behavior into the neural network. Tensor acceleration hardware continuously organizes and processes multi-dimensional data throughout the pipeline, while spatial processing modules manage image and video-related operations. At the same time, compression hardware reduces memory transfer overhead in the background.
Because these operations run simultaneously across dedicated hardware paths, the NPU can process large AI workloads with high throughput, lower latency, and far better power efficiency than traditional processors.
NPUs in Smartphones and Mobile AI
Modern smartphones handle a massive number of operations every second. A phone can unlock with facial recognition, open the camera, process photos, translate speech, and run AI-assisted applications almost instantly. To support this level of performance inside thin mobile devices with limited battery capacity, smartphones rely on highly integrated System-on-Chip (SoC) architectures.
Inside the SoC, multiple processors work together, and each processor is optimized for a different workload. The CPU manages system control, applications, and general computing tasks. The GPU handles graphics rendering, gaming, and visual processing. The NPU (Neural Processing Unit) focuses specifically on AI computation.
Instead of routing neural network workloads through the CPU or GPU, smartphones direct many AI tasks to the NPU, where the hardware is optimized for fast parallel AI processing. This separation improves efficiency because each processor handles the type of workload it was designed for. As a result, smartphones can perform advanced AI operations with faster response times, lower latency, and better power efficiency.
How NPUs Changed Smartphone AI
Before mobile NPUs became common, many smartphone AI features depended heavily on cloud computing. Tasks such as voice recognition, language translation, image enhancement, and intelligent assistants often required data to be uploaded to remote servers for processing before results were returned to the device. This created delays, increased network traffic, and raised privacy concerns.
The introduction of dedicated mobile NPUs changed this workflow significantly. AI models could now run directly on the smartphone itself, allowing many operations to execute locally in real time instead of depending entirely on external servers.
This shift provided several major advantages:
• Lower latency because data no longer needs constant cloud communication
• Faster AI response times during real-time operations
• Better privacy protection since sensitive data can remain on the device
• Lower power consumption through hardware optimized specifically for AI workloads
• More stable AI performance even with weak or unavailable internet connections
As mobile NPUs became more powerful, smartphones started running advanced AI features continuously in the background without noticeable delays during daily use.
How Smartphones Use NPUs in Real Operations
AI Photography and Image Processing
One of the most visible uses of mobile NPUs is AI photography. Modern smartphone cameras no longer rely only on image sensors and traditional image processing algorithms. AI models now analyze image data continuously while the camera is operating.
When the camera app opens, the smartphone immediately starts processing the incoming image stream frame by frame. The NPU analyzes lighting conditions, object boundaries, facial details, colors, textures, and movement patterns in real time. Based on this analysis, the system adjusts exposure, white balance, HDR settings, sharpness, and contrast almost instantly before the image is captured.
In low-light photography, the NPU combines multiple image frames together to improve brightness while reducing visual noise. During portrait photography, the processor separates foreground subjects from background areas and applies depth effects more accurately around edges such as hair, glasses, and clothing contours.
Scene recognition also depends heavily on the NPU. The processor compares image patterns against trained AI models to identify environments such as food, landscapes, pets, documents, sunsets, or night scenes. Once recognized, the camera automatically adjusts settings to optimize image quality.
Because these calculations occur directly on the smartphone, AI photography feels nearly instantaneous even though large amounts of neural network computation happen continuously in the background.
Voice Recognition and AI Assistants
Voice assistants and speech-related features also rely heavily on local AI acceleration. When a user speaks to the smartphone, the microphone captures raw audio signals that must be cleaned, separated, and converted into recognizable speech patterns.
The NPU continuously processes the audio stream by identifying phonemes, filtering background noise, and matching sound patterns against speech recognition models. Local AI processing allows wake words and common voice commands to be detected almost instantly without constantly transmitting audio recordings to cloud servers.
This improves responsiveness for tasks such as:
• Voice commands
• Real-time speech transcription
• Language translation
• AI assistant interaction
• AI call enhancement
• Noise suppression during video calls
Because much of the processing occurs directly on the device, voice interaction remains smoother even under unstable network conditions.
AI Gaming and Real-Time System Optimization
Modern smartphones also use NPUs for gaming optimization and intelligent system management. During gameplay, AI models monitor frame rendering demand, workload behavior, thermal conditions, touch input patterns, and battery usage in real time.
The system can dynamically adjust GPU workloads, optimize power allocation, stabilize frame rates, and reduce overheating during long gaming sessions. Some smartphones also use AI upscaling and motion prediction techniques to improve visual smoothness while maintaining lower power consumption.
Outside gaming, the NPU helps optimize background applications, battery management, predictive uer interactions, and task scheduling based on device usage patterns.
Evolution of Mobile NPUs
The development of mobile NPUs accelerated rapidly as smartphone AI workloads became more advanced and computationally demanding.
|
Period |
Mobile NPU Development |
|
2017 — Early Commercial Mobile NPUs |
Huawei introduced one of the first commercial smartphone
NPUs through the Kirin 970 processor. This marked a major shift toward
large-scale on-device AI acceleration inside consumer smartphones. Instead of
relying mainly on CPUs and GPUs for AI tasks, smartphones now included
dedicated AI hardware directly inside the SoC architecture. |
|
2018 — Expansion of On-Device AI |
Apple introduced the Neural Engine inside the A12 Bionic
chip, improving AI processing for facial recognition, computational
photography, and intelligent mobile features. On-device AI became a major
focus in flagship smartphone development. |
|
2019–2020 — Industry-Wide AI Integration |
Major chip manufacturers including Qualcomm, Samsung, and
MediaTek began integrating dedicated AI accelerators into flagship mobile
processors. AI performance started becoming a major competitive factor in
smartphone hardware design. |
|
2021–2023 — AI Processing Becomes a Core Benchmark |
Smartphone manufacturers increasingly compared NPU
performance alongside CPU and GPU performance. NPUs became central to
computational photography, voice AI, video enhancement, battery optimization,
and intelligent system features. |
|
2024–2025 — Large AI Models Running on Smartphones |
Modern mobile NPUs gained enough processing power to
support larger AI models directly on smartphones and edge devices. More AI
workloads could now run locally without depending heavily on cloud
infrastructure, improving both responsiveness and privacy. |
Comparison of Current Mainstream Mobile NPUs
Modern flagship smartphone processors now include highly advanced NPU architectures optimized for real-time AI inference, high throughput, and improved energy efficiency.
|
Mobile Processor |
NPU Features |
|
Apple A17 Pro |
Includes a 26-core Neural Engine designed for fast
on-device AI processing. The architecture improves AI photography, voice
recognition, and real-time intelligent system features across Apple devices. |
|
Qualcomm Snapdragon 8 Gen 3 |
Uses an upgraded Hexagon AI processor optimized for
generative AI, neural network acceleration, advanced image processing, and
efficient mobile AI workloads. |
|
MediaTek Dimensity 9300 |
Includes a sixth-generation APU (AI Processing Unit) with
major improvements in AI inference speed and real-time AI processing
capability for smartphones and edge devices. |
|
Samsung Exynos 2400 |
Features a next-generation mobile NPU focused on faster
on-device AI processing for computational photography, intelligent system
operations, and advanced mobile AI applications. |
NPU vs GPU vs CPU: Key Differences in AI Processing
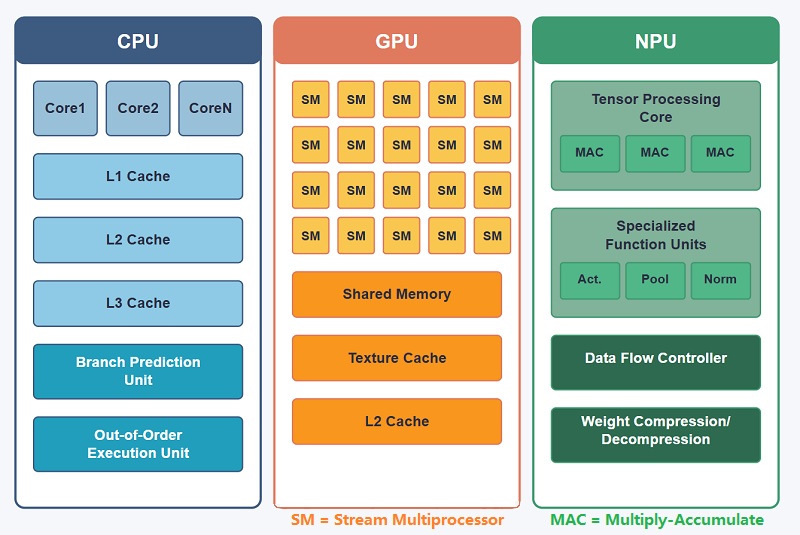
Both GPUs and NPUs are designed to process large amounts of data in parallel, but they were built for very different purposes. A GPU was originally developed for graphics rendering, while an NPU was created specifically for neural network computation and AI inference.Because of this difference in design goals, the two processors handle AI workloads in very different ways. GPUs can run AI models effectively, especially in large-scale training systems, but they still carry much of the complexity of a graphics processor. NPUs simplify many of these operations by focusing almost entirely on AI-related computation.
|
Feature |
CPU
(Central Processing Unit) |
GPU
(Graphics Processing Unit) |
NPU
(Neural Processing Unit) |
|
Main Purpose |
General-purpose
computing and system control |
Parallel
graphics and high-performance computation |
AI inference and
neural network acceleration |
|
Primary Workload |
Operating
systems, applications, multitasking |
Graphics
rendering, AI training, scientific computing |
AI processing,
tensor operations, deep learning inference |
|
Processing Style |
Sequential
processing |
Massive parallel
processing |
AI-optimized
parallel processing |
|
Core Design |
Few powerful and
flexible cores |
Thousands of
parallel execution cores |
Specialized AI
acceleration units |
|
AI Performance |
Moderate |
High |
Very High for AI
inference |
|
Matrix
Multiplication Speed |
Limited |
Fast |
Highly optimized |
|
Tensor
Processing |
Software-based |
Supported
through GPU acceleration |
Dedicated tensor
acceleration hardware |
|
Power Efficiency |
Lower for AI
workloads |
Moderate to high
power consumption |
Highly power
efficient |
|
Heat Generation |
Moderate |
High under heavy
workloads |
Lower during AI
inference |
|
Memory Bandwidth
Usage |
Moderate |
Very high |
Optimized and
reduced |
|
Latency in AI
Tasks |
Higher |
Moderate |
Very low |
|
Real-Time AI
Capability |
Limited |
Good |
Excellent |
|
Best for AI
Training |
Not ideal |
Excellent |
Limited compared
to GPUs |
|
Best for AI
Inference |
Basic workloads |
High-performance
inference |
Optimized
real-time inference |
|
Common
Applications |
PCs, servers,
operating systems |
Gaming, AI
training, rendering, simulations |
Smartphones,
edge AI, robotics, smart cameras |
|
Dependence on
Cloud AI |
Higher |
Moderate |
Lower due to
local AI acceleration |
|
Battery
Efficiency in Mobile Devices |
Lower |
Moderate |
High |
|
Typical Devices |
Computers,
laptops, servers |
Gaming PCs, AI
servers, workstations |
Smartphones, IoT
devices, edge AI hardware |
|
Cost and
Complexity |
General-purpose
architecture |
Complex
high-performance architecture |
Specialized
AI-focused architecture |
|
Main Advantage |
Flexibility and
system management |
Large-scale
parallel computation |
Fast and
efficient local AI processing |
Specialized Processing Units in Modern Computing
Aside from NPU, modern computing systems use many different types of processors because no single architecture can efficiently handle every workload. Some processors focus on system control, some specialize in graphics rendering, while others are optimized for AI acceleration, networking, scientific computing, or embedded control.
Inside modern smartphones, servers, industrial systems, robotics platforms, vehicles, and edge AI devices, multiple processing units often work together simultaneously. Each processor handles the type of workload it was specifically designed for, improving performance, power efficiency, and real-time responsiveness across modern computing environments.
CPU: Central Processing Unit
A CPU (Central Processing Unit) is the main controller of most computing systems. It manages operating systems, applications, memory coordination, task scheduling, and communication between hardware components.
CPUs are highly flexible and can handle many different workloads reliably, making them essential in computers, smartphones, servers, and embedded systems. However, they are less efficient for large-scale parallel AI workloads compared to more specialized processors.
GPU: Graphics Processing Unit
A GPU (Graphics Processing Unit) is optimized for large-scale parallel processing. The architecture contains many execution cores capable of handling thousands of operations simultaneously.
GPUs were originally developed for graphics rendering, but they are now widely used for AI training, scientific simulation, video processing, and high-performance computing because of their strong parallel computation capability.
TPU: Tensor Processing Unit
A TPU (Tensor Processing Unit) is optimized for tensor-based AI workloads and large-scale deep learning acceleration. These processors are designed mainly for cloud AI infrastructure and data-center machine learning environments.
TPUs are highly effective for:
• Deep learning training
• Large AI models
• Tensor computation
• Cloud AI services
• High-throughput AI acceleration
FPGA: Reconfigurable Hardware Processing
An FPGA (Field-Programmable Gate Array) uses programmable logic blocks that can be configured for specific tasks after manufacturing. Unlike fixed processor architectures, FPGAs allow the hardware function itself to be customized.
FPGAs are widely used in:
• Communication systems
• Automotive electronics
• Industrial automation
• Aerospace systems
• Edge computing
• Medical devices
DPU: Data Processing Unit
A DPU (Data Processing Unit) is optimized for data-centric workloads inside cloud infrastructure and networking systems. DPUs help reduce CPU workload by accelerating data movement, storage operations, encryption, and network traffic management.
These processors are commonly used in:
• Data centers
• Cloud computing
• High-speed networking
• Storage acceleration
• Server infrastructure
VPU: Vision Processing Unit
A VPU (Vision Processing Unit) specializes in computer vision and image-based AI processing. VPUs accelerate workloads such as facial recognition, object detection, motion tracking, and video analysis.
VPUs are commonly found in:
• Smart cameras
• Surveillance systems
• Robotics
• Autonomous vehicles
• AR/VR systems
• Edge AI vision devices
IPU: Intelligence Processing Unit
An IPU (Intelligence Processing Unit) is designed for highly parallel AI and machine learning workloads. The architecture focuses on improving data flow efficiency during large-scale neural network execution.
IPUs are used for:
• Machine learning acceleration
• Pattern recognition
• AI inference
• Parallel tensor processing
• Advanced AI research
BPU: Brain Processing Unit
A BPU (Brain Processing Unit) is optimized for embedded AI and edge intelligence systems. These processors focus on fast local AI inference with lower power consumption.
BPUs are commonly used in:
• Smart sensing systems
• Robotics
• Edge AI hardware
• Motion detection systems
• Autonomous platforms
HPU: Holographic Processing Unit
An HPU (Holographic Processing Unit) is designed for holographic computing, mixed reality, and spatial analysis systems.
HPUs help process:
• Environmental mapping
• Motion tracking
• Sensor fusion
• Real-time spatial interaction
• AR/VR environments
MPU and MCU: Embedded Control Processing
MPUs (Microprocessor Units) and MCUs (Microcontroller Units) are widely used in embedded systems and low-power electronics.
MPUs are commonly used in embedded computing systems that require operating-system-level control, while MCUs integrate processor cores, memory, and input/output control into a compact chip for dedicated low-power tasks.
These processors are commonly found in:
• IoT devices
• Industrial controllers
• Automotive electronics
• Home appliances
• Portable embedded systems
APU: Accelerated Processing Unit
An APU (Accelerated Processing Unit) combines CPU and GPU functionality inside a single processor package. This integration improves power efficiency, reduces hardware size, and allows computing and graphics workloads to share system resources more efficiently.
APUs are commonly used in:
• Laptops
• Mini PCs
• Entry-level gaming systems
• Multimedia devices
• Portable computing platforms
Why Modern Systems Use Multiple Specialized Processors
Modern computing systems rarely rely on a single processor architecture. Instead, devices combine multiple specialized processors together because different workloads require different processing methods.
For example, a modern system may use:
• CPUs for system control
• GPUs for graphics and parallel computation
• NPUs for AI inference
• VPUs for computer vision
• DPUs for networking and data movement
• MCUs for embedded control tasks
By distributing workloads across dedicated hardware, modern systems achieve better performance, lower latency, improved energy efficiency, and more effective real-time processing across AI, graphics, networking, and embedded computing environments.
Conclusion
NPUs are becoming essential in modern computing because they allow AI tasks to run locally, quickly, and efficiently without depending heavily on cloud processing. Their optimized architecture reduces latency, power use, memory movement, and heat generation, making them valuable in smartphones, robotics, healthcare devices, industrial automation, smart homes, autonomous systems, and edge AI platforms. As AI models become larger and more complex, future NPUs will continue improving through smarter architectures, low-precision computing, in-memory processing, local large-model support, advanced semiconductor design, and stronger AI security features.
Frequently Asked Questions [FAQ]
1. Why are NPUs more efficient than CPUs for neural network workloads?
NPUs are more efficient because their hardware is designed specifically for AI computation instead of general-purpose processing. A CPU handles many different system tasks sequentially, while an NPU focuses mainly on tensor operations, matrix multiplication, convolution, and parallel neural network processing. This allows NPUs to complete AI inference faster while using less power and generating less heat.
2. How does parallel processing improve NPU performance during AI inference?
NPUs divide AI workloads into many smaller operations that run simultaneously across multiple computing units. Instead of waiting for one instruction to finish before starting another, large amounts of neural-network data move through the processor in parallel. This significantly improves throughput and reduces latency during workloads such as image recognition, speech processing, and real-time object detection.
3. Why is low-precision computing important in modern NPUs?
Many AI models do not require extremely high numerical precision to produce accurate results. NPUs use formats such as INT8 and FP16 to reduce memory usage and computational overhead. Lower-precision processing allows more operations to be completed in less time while improving energy efficiency and maintaining strong AI inference performance.
4. How do NPUs reduce memory-transfer bottlenecks compared to GPUs?
NPUs place memory and computation hardware closer together inside the processor architecture. Instead of repeatedly transferring large amounts of tensor data between external memory and processing cores, many intermediate operations remain near the execution units. This shortens data paths, reduces bandwidth usage, lowers latency, and improves overall power efficiency.
5. Why are NPUs becoming useful in smartphones and edge AI devices?
Modern devices require fast local AI processing with low power consumption and minimal latency. NPUs allow smartphones and edge systems to perform AI tasks such as facial recognition, AI photography, voice interaction, and object detection directly on the device without depending heavily on cloud servers. This improves responsiveness, privacy, and battery efficiency.
6. How do MAC units contribute to NPU acceleration?
Multiply-Accumulate (MAC) units handle the repeated multiplication and addition operations used throughout neural networks. Modern NPUs contain hundreds or thousands of MAC units working simultaneously, allowing large AI workloads to be processed much faster than on traditional sequential processors.
7. Why do modern AI systems use both GPUs and NPUs instead of relying on one processor type?
GPUs and NPUs are optimized for different workloads. GPUs excel at large-scale AI training, graphics rendering, and high-performance parallel computation, while NPUs are optimized for low-power AI inference and real-time local processing. Using both processors together allows systems to balance flexibility, performance, and energy efficiency.
8. How do NPUs improve real-time AI processing in robotics and autonomous systems?
Robotics and autonomous systems continuously process camera input, environmental mapping, sensor data, and motion analysis. NPUs accelerate these workloads locally with low latency, allowing systems to react quickly during navigation, obstacle detection, pedestrian recognition, and real-time decision-making.
9. Why is on-device AI becoming more important for future NPU development?
On-device AI reduces dependence on cloud computing by allowing AI models to run directly on local hardware. This improves privacy, lowers network bandwidth usage, and enables faster real-time responses. Future NPUs are expected to support larger local AI models, multimodal AI processing, and advanced generative AI workloads directly inside consumer and industrial devices.
10. How could future NPU architectures change AI hardware efficiency?
Future NPUs will likely use smarter workload allocation, sparse computing, in-memory processing, chiplet architectures, and adaptive precision control to improve efficiency. These technologies aim to reduce unnecessary computation, lower power consumption, and increase throughput while supporting larger and more advanced AI models across edge devices, robotics, industrial systems, and intelligent consumer electronics.
Related Blog
-
How Many Zeros in a Million, Billion, Trillion?
![How Many Zeros in a Million, Billion, Trillion?]()
July 29th, 2024
Million represents 106, an easily graspable figure when compared to everyday items or annual salaries. Billion, equivalent to 109, starts to stretch t... -
IRLZ44N MOSFET Datasheet, Circuit, Equivalent, Pinout
![IRLZ44N MOSFET Datasheet, Circuit, Equivalent, Pinout]()
August 28th, 2024
The IRLZ44N is a widely-used N-Channel Power MOSFET. Renowned for its excellent switching capabilities, it is highly suited for numerous applications,... -
Battery Temperature Too Low, Charging Stopped. How to Fix It?
![Battery Temperature Too Low, Charging Stopped. How to Fix It?]()
October 6th, 2024
Mobile phone battery charging issues are common but can be effectively managed. Temperature plays a big role in battery efficiency, as smartphone batt... -
BC547 Transistor Comprehensive Guide
![BC547 Transistor Comprehensive Guide]()
July 4th, 2024
The BC547 transistor is commonly used in a variety of electronic applications, ranging from basic signal amplifiers to complex oscillator circuits and... -
Comprehensive Guide to SCR (Silicon Controlled Rectifier)
![Comprehensive Guide to SCR (Silicon Controlled Rectifier)]()
April 22th, 2024
Silicon Controlled Rectifiers (SCR), or thyristors, play a pivotal role in power electronics technology because of their performance and reliability. ... -
LR621, SR621SW, 364, AG1 Battery Equivalents and Replacements
![LR621, SR621SW, 364, AG1 Battery Equivalents and Replacements]()
July 15th, 2024
LR621 and SR621SW button batteries are prevalent in compact electronic devices like watches, small toys, calculators, and remote keys. Multiple manufa... -
Fundamentals of Op-Amp Circuits
![Fundamentals of Op-Amp Circuits]()
December 28th, 2023
In the intricate world of electronics, a journey into its mysteries invariably leads us to a kaleidoscope of circuit components, both exquisite and co... -
Comparing NMOS and PMOS Differences and Applications
![Comparing NMOS and PMOS Differences and Applications]()
November 15th, 2024
Understanding the differences between NMOS and PMOS transistors is important in designing efficient circuits. NMOS (N-type Metal-Oxide-Semiconductor) ... -
A Complete Guide to Multiplexers and Their Role in Digital Systems
![A Complete Guide to Multiplexers and Their Role in Digital Systems]()
September 20th, 2025
Multiplexers are components in digital systems, designed to channel multiple input signals into a single output line using binary logic and control si... -
What Do STD, AGM, and Gel Mean On a Battery Charger
![What Do STD, AGM, and Gel Mean On a Battery Charger]()
July 10th, 2024
Traditional lead-acid battery chargers are known for their simplicity and reliability. They have been serving their purpose effectively for years, lar...










Hot Parts
- TPS62007DGS
- MCIMX31LCVKN5D
- 12065C392JAT2A
- MEC5035-NU-KMV
- M27C256B-12C6
- 06033A330J4T2A
- PS4043FL-G
- PI74FCT2245TQA
- 6SY7000-0AC37
- PI4MSD5V9543ALEX
- UKL1H100KDDANA
- EPM570GT100I5
- 06033C102KAT7A
- M37902FGCHP
- GTL2006PW
- C2012X5R1A225K085AA
- XC2S100-6FG456C
- NJG1116BHB3
- F930G686MAA
- AM29BDD160GB65ADEH1
- TXB0304RSVR
- SI6874EDQ-T1
- LTC2954ITS8-1#TRMPBF
- ISL12022MIBZ-TR5421
- CGJ5H4X7R2H152K115AA
- MX30LF2G18AC-XKI
- GRM0336R1E3R2CD01D
- GRM31CR61A475KA01K
- AD2C541S
- TAJS225K010RNJ
- XC9536XL-10VQG44Q
- MAX6952EAX+
- 06033A4R0BAT2A
- SN75LV4737ADBRG4
- LM25011AMYX
- 2SK880-Y
- AD8392AAREZ
- 0603YC105KAT2A
- Z0861112VSC
- RC0402FR-07402KL
- UCC21520DW
- VE-J3Z-CY
- T491X107M020ZT7027
- T491C106K016AT40817622
- MT48LC4M32B2-7F
- VSC8117QP1
- MSD5043-P00-DA0
- BU6744KV
- CC0805KRX7R0BB104
- MFC110-16-223F3TD